标签搜索


找到
15
篇与
相关的结果
-
 Cgroups资源限制 一、Cgroups介绍Cgroups是什么?Cgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。最初由google的工程师提出,后来被整合进Linux内核。Cgroups也是LXC为实现虚拟化所使用的资源管理手段,可以说没有cgroups就没有LXC。Cgroups可以做什么?Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。Cgroups提供了一下功能:限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。Cgroups相关概念及其关系相关概念1.任务(task)。在cgroups中,任务就是系统的一个进程。 2.控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用cgroups以控制族群为单位分配的资源,同时受到cgroups以控制族群为单位设定的限制。 3.层级(hierarchy)。控制族群可以组织成hierarchical的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。 4.子系统(subsytem)。一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。相互关系1.每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup ,此cgroup在创建层级时自动创建,后面在该层级中创建的cgroup都是此cgroup的后代)的初始成员。 2.一个子系统最多只能附加到一个层级。 3.一个层级可以附加多个子系统 4.一个任务可以是多个cgroup的成员,但是这些cgroup必须在不同的层级。 5.系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的cgroup。 二、Cgroups子系统介绍blkio 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。cpu 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。cpuacct 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。cpuset 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。devices 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。freezer 这个子系统挂起或者恢复 cgroup 中的任务。memory 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。net_cls 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。ns 名称空间子系统。理解三句话1)任何单一子系统最多可以附加到一个层级。2)单一层级可以被附加一个或多个子系统 比如:cpuset cpu memory 附加到cpu_and_memory层3)每次创建新的层级时,该系统中的所有进程都是那个层级的默认CGroup的初始成员。对于创建的任何单一层级,该系统中的每个进程都可以是那个层级中唯一一个CGroup的成员。单一进程可以在多个CGroup中时,只要保证每个CGroup不在相同层级中即可。当在同一级冲突时,进程作为第二个CGroup的成员,会将自己从第一个CGroup中删除三、cgroups安装1、安装cgroup[root@localhost ~]# yum -y install libcgroup2、启动前查看cgroup分层挂载[root@localhost ~]# lssubsys #显示为空3、启动cgroup[root@localhost ~]# /etc/init.d/cgconfig start Starting cgconfig service: [确定]4、验证安装#启动成功后再次执行 [root@localhost ~]# lssubsys cpuset cpu cpuacct memory devices freezer net_cls blkio #查看挂载情况 [root@localhost ~]# lssubsys -am 显示挂载情况 ns perf_event net_prio cpuset /cgroup/cpuset cpu /cgroup/cpu cpuacct /cgroup/cpuacct memory /cgroup/memory devices /cgroup/devices freezer /cgroup/freezer net_cls /cgroup/net_cls blkio /cgroup/blkio #cgroup 目录不在为空 [root@localhost ~]# ls /cgroup/ blkio cpu cpuacct cpuset devices freezer memory net_cls5、配置文件/etc/cgconfig.conf 定义挂载子系统三、限制进程资源使用1、cgroup分组管理新建分组mkdir /cgroup/cpu/baism_testor[root@localhost opt]# cgcreate -g memory:/baism_test 使用命令创建 在内存分组下创建一个分组 baism_test删除分组[root@localhost opt]# cgdelete -r cpu:/baism_test 删除分组 cpu/baism_test2、设置分组资源应用阈值2.1、限制一个进程使用cpu[root@localhost opt]# echo 50000 > /cgroup/cpu/baism_test/cpu.cfs_quota_us 设置进程使用CPU的百分比是50%验证CPU设置#方法一 创建一个跑CPU的进程 use_cpu.sh #!/bin/bash x=0 echo "current_process_number is : $$" while [ True ];do x=$x+1 done 将该进程的进程号加入资源分组baism_test [root@localhost cgroup]# echo 5398 > /cgroup/cpu/baism_test/tasks 将运行的程序的进程号输入到task中就行 #通过TOP查看进程使用CPU在合理范围内 结束程序后 进程从tasks中消失 #方法二 使用cgexec命令对新启动的程序设置 限制 [root@localhost opt]# cgexec -g cpu:/baism_test /opt/use_cpu.sh2.2、限制一个程序使用内存 最大1M 1048676字节[root@localhost cgroup]# echo 1048576 > memory/baism_test/memory.limit_in_bytes验证内存限制##将进程号加入资源分组 [root@localhost cgroup]# echo 5584 > memory/baism_test/tasks or 开启任务的时候直接加入资源分组 [root@localhost opt]# cgexec -g memory:/baism_test /opt/use_memory.sh 可以看出 程序使用到最大的时候 就会被Kill掉 测试的时候 先运行程序在运行限制 就不会上来就是杀死状态了2.3、限制进程对IO的使用 限制读为1M#设置资源分组IO的限制[root@localhost opt]# cgcreate -g blkio:/baism_test [root@localhost opt]# echo '8:0 1048676' > /cgroup/blkio/baism_test/blkio.throttle.read_bps_device验证IO限制[root@localhost opt]# dd if=/dev/sda of=/dev/null & [1] 5615 [root@localhost opt]# echo 5615 > /cgroup/blkio/baism_test/tasks [root@localhost opt]# 通过iotop可以看出 读取下降到了1M
Cgroups资源限制 一、Cgroups介绍Cgroups是什么?Cgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。最初由google的工程师提出,后来被整合进Linux内核。Cgroups也是LXC为实现虚拟化所使用的资源管理手段,可以说没有cgroups就没有LXC。Cgroups可以做什么?Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。Cgroups提供了一下功能:限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。Cgroups相关概念及其关系相关概念1.任务(task)。在cgroups中,任务就是系统的一个进程。 2.控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用cgroups以控制族群为单位分配的资源,同时受到cgroups以控制族群为单位设定的限制。 3.层级(hierarchy)。控制族群可以组织成hierarchical的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。 4.子系统(subsytem)。一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。相互关系1.每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup ,此cgroup在创建层级时自动创建,后面在该层级中创建的cgroup都是此cgroup的后代)的初始成员。 2.一个子系统最多只能附加到一个层级。 3.一个层级可以附加多个子系统 4.一个任务可以是多个cgroup的成员,但是这些cgroup必须在不同的层级。 5.系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的cgroup。 二、Cgroups子系统介绍blkio 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。cpu 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。cpuacct 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。cpuset 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。devices 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。freezer 这个子系统挂起或者恢复 cgroup 中的任务。memory 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。net_cls 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。ns 名称空间子系统。理解三句话1)任何单一子系统最多可以附加到一个层级。2)单一层级可以被附加一个或多个子系统 比如:cpuset cpu memory 附加到cpu_and_memory层3)每次创建新的层级时,该系统中的所有进程都是那个层级的默认CGroup的初始成员。对于创建的任何单一层级,该系统中的每个进程都可以是那个层级中唯一一个CGroup的成员。单一进程可以在多个CGroup中时,只要保证每个CGroup不在相同层级中即可。当在同一级冲突时,进程作为第二个CGroup的成员,会将自己从第一个CGroup中删除三、cgroups安装1、安装cgroup[root@localhost ~]# yum -y install libcgroup2、启动前查看cgroup分层挂载[root@localhost ~]# lssubsys #显示为空3、启动cgroup[root@localhost ~]# /etc/init.d/cgconfig start Starting cgconfig service: [确定]4、验证安装#启动成功后再次执行 [root@localhost ~]# lssubsys cpuset cpu cpuacct memory devices freezer net_cls blkio #查看挂载情况 [root@localhost ~]# lssubsys -am 显示挂载情况 ns perf_event net_prio cpuset /cgroup/cpuset cpu /cgroup/cpu cpuacct /cgroup/cpuacct memory /cgroup/memory devices /cgroup/devices freezer /cgroup/freezer net_cls /cgroup/net_cls blkio /cgroup/blkio #cgroup 目录不在为空 [root@localhost ~]# ls /cgroup/ blkio cpu cpuacct cpuset devices freezer memory net_cls5、配置文件/etc/cgconfig.conf 定义挂载子系统三、限制进程资源使用1、cgroup分组管理新建分组mkdir /cgroup/cpu/baism_testor[root@localhost opt]# cgcreate -g memory:/baism_test 使用命令创建 在内存分组下创建一个分组 baism_test删除分组[root@localhost opt]# cgdelete -r cpu:/baism_test 删除分组 cpu/baism_test2、设置分组资源应用阈值2.1、限制一个进程使用cpu[root@localhost opt]# echo 50000 > /cgroup/cpu/baism_test/cpu.cfs_quota_us 设置进程使用CPU的百分比是50%验证CPU设置#方法一 创建一个跑CPU的进程 use_cpu.sh #!/bin/bash x=0 echo "current_process_number is : $$" while [ True ];do x=$x+1 done 将该进程的进程号加入资源分组baism_test [root@localhost cgroup]# echo 5398 > /cgroup/cpu/baism_test/tasks 将运行的程序的进程号输入到task中就行 #通过TOP查看进程使用CPU在合理范围内 结束程序后 进程从tasks中消失 #方法二 使用cgexec命令对新启动的程序设置 限制 [root@localhost opt]# cgexec -g cpu:/baism_test /opt/use_cpu.sh2.2、限制一个程序使用内存 最大1M 1048676字节[root@localhost cgroup]# echo 1048576 > memory/baism_test/memory.limit_in_bytes验证内存限制##将进程号加入资源分组 [root@localhost cgroup]# echo 5584 > memory/baism_test/tasks or 开启任务的时候直接加入资源分组 [root@localhost opt]# cgexec -g memory:/baism_test /opt/use_memory.sh 可以看出 程序使用到最大的时候 就会被Kill掉 测试的时候 先运行程序在运行限制 就不会上来就是杀死状态了2.3、限制进程对IO的使用 限制读为1M#设置资源分组IO的限制[root@localhost opt]# cgcreate -g blkio:/baism_test [root@localhost opt]# echo '8:0 1048676' > /cgroup/blkio/baism_test/blkio.throttle.read_bps_device验证IO限制[root@localhost opt]# dd if=/dev/sda of=/dev/null & [1] 5615 [root@localhost opt]# echo 5615 > /cgroup/blkio/baism_test/tasks [root@localhost opt]# 通过iotop可以看出 读取下降到了1M -
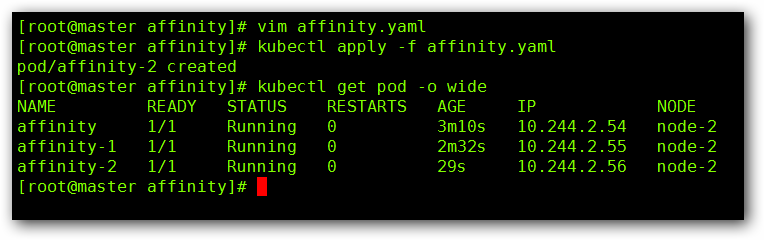
Kubernetes节点与 Pod 亲和性 一、节点亲和性策略介绍pod.spec.nodeAffinitypreferredDuringSchedulingIgnoredDuringExecution:软策略requiredDuringSchedulingIgnoredDuringExecution:硬策略preferred:首选,较喜欢 required:需要,必修键值运算关系:In:label 的值在某个列表中NotIn:label 的值不在某个列表中Gt:label 的值大于某个值Lt:label 的值小于某个值Exists:某个 label 存在DoesNotExist:某个 label 不存在二、节点与Pod硬亲和性requiredDuringSchedulingIgnoredDuringExecution#创建pod的模板yaml文件 vim affinity.yaml apiVersion: v1 kind: Pod metadata: name: affinity labels: app: node-affinity-pod spec: containers: - name: with-node-affinity image: docker.io/nginx affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: NotIn values: - node-1通过修改 Pod 名称的方式多创建几个 Pod 查看结果:这个时候,我们将 operator 修改为 “In” ,node-1 修改为 node-3,vim affinity.yaml apiVersion: v1 kind: Pod metadata: name: affinity-3 labels: app: node-affinity-pod spec: containers: - name: with-node-affinity image: docker.io/nginx affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node-3查看下结果:这个时候可以看到,我们新创建的 Pod 一直处于 Pending 的状态,这是因为我们没有Node-3这个节点,且采用的是硬亲和性策略的原因所导致的。三、节点与Pod软亲和性preferredDuringSchedulingIgnoredDuringExecution为了解决上述因为硬亲和性创建Pod不成功的问题,我们通过设置软亲和性策略后再次创建一个pod affinity-pod-a测试。vim affinity-1.yaml apiVersion: v1 kind: Pod metadata: name: affinity-a labels: app: node-affinity-pod-a spec: containers: - name: with-node-affinity-a image: docker.io/nginx affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: kubernetes.io/hostname operator: In values: - node-3我们没有 node-3 节点,这个时候我们创建看一下:我们再将 node-3 修改为 node-1 看一下:通过实验我们得出关于节点与pod亲和力策略硬限制是:我必须在某个节点或我必须不在某个节点。软限制是:我想在某个节点或我不想在某个节点,实在不行,我也可以将就。软硬限制结合策略策略优先级:先满足硬限制,然后满足软限制软硬限制可以结合使用,先满足硬限制,然后满足软限制= apiVersion: v1 kind: Pod metadata: name: affinity labels: app: node-affinity-pod spec: containers: - name: with-node-affinity image: docker.io/nginx affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: NotIn values: - node-2 preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: source operator: In values: - zutuanxue_com四、Pod 亲和性pod.spec.affinity.podAffinity/podAntiAffinitypreferredDuringSchedulingIgnoredDuringExecution:软策略requiredDuringSchedulingIgnoredDuringExecution:硬策略podAffinity: pod之间亲和,pod在同一网段 podAntiAffinity:pod之间反亲和,pod在不同网段4.1、pod亲和性vim test-pod.yaml apiVersion: v1 kind: Pod metadata: name: pod-1 labels: app: pod-1 spec: containers: - name: pod-1 image: docker.io/busybox command: [ "/bin/sh", "-c", "sleep 600s" ] #-----------------------------# 分割线 #--------------------------------------# vim affinity-pod.yaml apiVersion: v1 kind: Pod metadata: name: pod-3 labels: app: pod-3 spec: containers: - name: pod-3 image: docker.io/nginx affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - pod-1 topologyKey: kubernetes.io/hostname我们来看一下结果:五、关于亲和性总结调度策略匹配标签操作符拓扑域支持调度目标nodeAffinity主机In, NotIn, Exists,DoesNotExist, Gt, Lt否指定主机podAffinityPODIn, NotIn, Exists,DoesNotExist是POD与指定POD同一拓扑域podAnitAffinityPODIn, NotIn, Exists,DoesNotExist是POD与指定POD不在同一拓扑域
-
结构体指针 指针初始化直接使用ip是地址,*ip是取值(18)func main() { var ( a int = 18 //声明实际变量 ip *int //声明指针变量 ) ip = &a //把a的地址赋给ip指针 fmt.Println("a变量的值是: ", a) fmt.Println("a变量的地址是: ", &a) fmt.Println("指针ip的值为: ", ip) fmt.Println("指针ip指向的值为: ", *ip) } //输出结果如下 a变量的值是: 18 a变量的地址是: 0xc0000aa058 指针ip的值为: 0xc0000aa058 指针ip指向的值为: 18未取初始化的指针值默认为<nil>func main() { var age *int fmt.Println(age) } <nil>结构体类型指针type Person1 struct { name string } func main() { p := Person1{ "wang", } var po *Person1 = &p fmt.Println(po) } &结构体初始化方法(==指针初始化推荐使用new函数==)//1 func main() { p1 := &Person } //2 func main() { var testPerson Person p2 := &testPerson } //3 func main() { var testPerson = new(Person) fmt.Println(testPerson.name) } 可使用简洁定义func main() { p := Person1{ "wang", } po := &p fmt.Println(po) fmt.Printf("%T", po) } & *main.Person1
-
结构体绑定方法 结构体绑定方法Go结构体方法没有封装在结构体内部,这样结构体架构很清晰。==通常结构体方法定义在结构体外部,定义函数时绑定结构体。==func (p Person) print() { //关键字 (内部使用名 结构体) 函数名() 返回值 // 接收器(值传递) fmt.Printf("name: %s,age: %d\n", p.name, p.age) } func (p Student) print1() { fmt.Printf("score: %0.2f,name: %s\n", p.score, p.name) }初始化并使用方法;func main() { s := Student{ Person{ "wangtao", 30, }, 560, "jiaobao", } s.print1() } // score: 560.00,name: jiaobao
-
结构体嵌套 结构体嵌套type Person struct { name string age int } type Student struct { p Person //结构体类型 score float32 } func main() { s := Student{ Person{ "wang", 19, }, 29, } fmt.Println(s.p, s.score) }//s.p.name 29匿名嵌套s.==p==.name 想不走p类型直接取到p的成员变量type Student struct { Person //不写成员变量名字 score float32 } func main() { s := Student{ Person{ "wang", 19, }, 29, } fmt.Println(s.name, s.age) //直接取到Person成员 } wang 19嵌套内部相同的变量名优先级小于嵌套外部type Person struct { name string age int } type Student struct { Person name string } func main() { s := Student{ Person{ "wang", 19, }, "tao", } fmt.Println(s.name) } tao对相同名字的变量赋值或操作 优先使用的是外部结构体的变量。